

In June of 2014, the Delta Science Program hosted an Environmental Data Summit, which brought together scientists, managers, and experts to discuss how to increase data and information sharing using new technologies. A white paper will soon be released, which details the challenges, solutions, and strategies gathered from summit participants.
In the first part of this post, Rainer Hoenicke from the Delta Science Program previews some of the highlights of the white paper. He is then followed by Toni Hale, program director for environmental informatics at SFEI Aquatic Science Center, discusses the challenges and opportunities for implementing successful business models to sustainably address the state’s technology needs.
Rainer Hoenicke
 Rainer Hoenicke began by referring to the video clip from the Ted talk that Dr. Peter Goodwin showed as part of his speech at the plenary session (LINK), and said that the Delta Science Program wants to create the same momentum with the Delta Science Plan. “Out of that comes the science action agenda that we really want to implement and start doing with the same momentum that was in the movie yesterday, with somebody starting the movement and slowly and gradually people deciding to join in and really creating synergies,” he said.
Rainer Hoenicke began by referring to the video clip from the Ted talk that Dr. Peter Goodwin showed as part of his speech at the plenary session (LINK), and said that the Delta Science Program wants to create the same momentum with the Delta Science Plan. “Out of that comes the science action agenda that we really want to implement and start doing with the same momentum that was in the movie yesterday, with somebody starting the movement and slowly and gradually people deciding to join in and really creating synergies,” he said.
One of the key implementation steps articulated in the Delta Science Plan was to develop the infrastructure, capacity, and tools to do the science, so the science plan charged the science program with hosting an Environmental Data Summit, and to develop guidelines for data sharing which was held in June of 2014, he said. “We gathered everybody around the table that had some interest, either that was in the data generation community out with boats and dumping their data into a spreadsheet and hopefully a database somewhere, and then figuring out from the data users what are their needs were, and one of the key themes that ran through it was data access and integration.”
“Every program has their own goals and objectives and generates their own data, but it’s really hard to synthesize that and tell a story from all of the data that are out there that can contribute to our state of knowledge,” he said.
Rainer then presented a slide with a quote from Peter Drucker that said, ‘Information is data empowered with relevance and purpose.’ “Why do we want to improve data integration? Why do we care about it? Let me unpack some of the meaning behind Peter Drucker’s quote,” he said. “How does the theme of decision making in the rapidly changing environment fit in with data integration? Data alone do not lend themselves to making decisions,” Mr. Hoenicke said. He then listed three important things that are needed so that data can be used in the decision making process:
- Relevance or saliency: “If you don’t have access to data in time to inform an upcoming management decision, they are not relevant anymore, so if you sit on data for years and years and nobody knows about it, they are not part of best available science.”
- Credibility: “This includes two important aspects: scientific rigor and sufficient data documentation. If you have no clue what uses you can subject the data to, they are commonly known as bad data. There shouldn’t be such a thing as bad data, only ill-documented data.”
- Legitimacy: “This includes ready availability to all who would like to analyze and synthesize the data or subsets of data. Legitimacy also includes transparency to those who make decisions and those affected be decisions.”
In 2012, the National Research Council wrote, ‘Only a synthetic, integrated, analytical approach to understanding the effects of suites of environmental factors [stressors] on the ecosystem and its components is likely to provide important insights that can lead to the enhancement of the Delta and its species.’ Mr. Hoenicke said that only through data integration can we get beyond the information silos that exist in our world currently.
“This sounds like a reasonable charge at first glance,” he said. “But what it really means is that we have to get to the data behind each major stressor category, such as effects of channels cutoff from their floodplains, diverting roughly 50% of flows from the watershed before it even gets through the Golden Gate, invasions of non-native species, excessive nutrient loads and toxic contaminants, because all of these stressors interact with each other and without being able to connect these stressors and tell a comprehensive story of the integrated effects, we will never get anywhere.”
“To make things even more complicated, we also need data on the type, magnitude, and frequency of intervention actions so we can derive a line of evidence what worked and what didn’t,” he said. Data is needed for the condition and the stressors that act upon the environmental parameters as well as the effects of intervention actions.
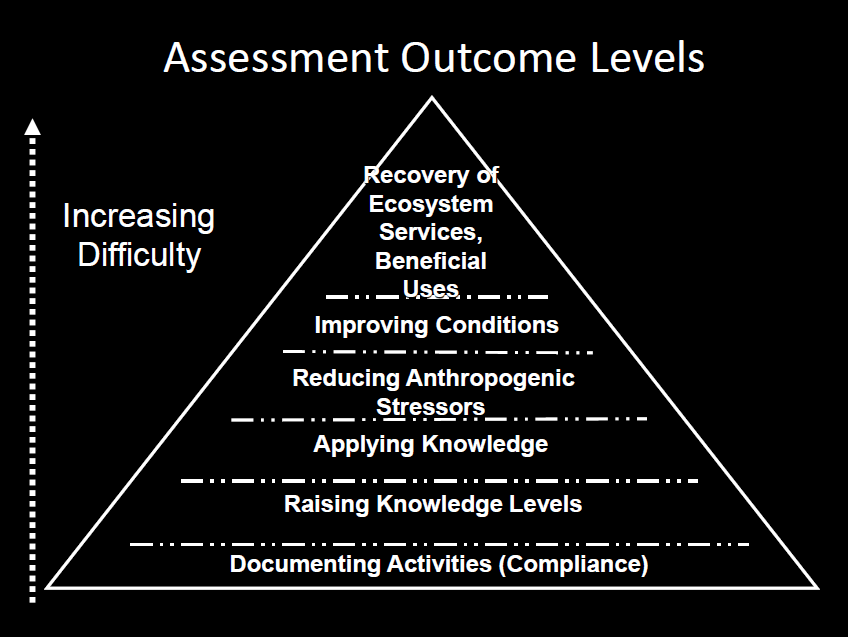 He then presented a slide with a pyramid chart on it. “As you go up the pyramid, you encounter increasingly difficult challenges,” he said. “We need data for all six tiers here. The further up you go, the more data we need to combine to assess outcomes so you can make better decisions over time. Assuming for a moment that data are actually collected for each one of these tiers, and that’s a big assumption, do we know where they are housed? Do we know what questions they are capable of answering? Do we know form they are in? Do we really know if they are complete or if we have access to only 10% of relevant data?”
He then presented a slide with a pyramid chart on it. “As you go up the pyramid, you encounter increasingly difficult challenges,” he said. “We need data for all six tiers here. The further up you go, the more data we need to combine to assess outcomes so you can make better decisions over time. Assuming for a moment that data are actually collected for each one of these tiers, and that’s a big assumption, do we know where they are housed? Do we know what questions they are capable of answering? Do we know form they are in? Do we really know if they are complete or if we have access to only 10% of relevant data?”
So while we have made lots of steps in the right direction, to tackle questions like these and to meet one of the major overarching challenges that the NRC gave us, we need a greater focus on data integration, he said.
 Mr. Hoenicke then listed the challenges to data integration:
Mr. Hoenicke then listed the challenges to data integration:
- Expectations for “transparency”: “The expectations of data users have changed quite a bit over time. In the past, sending a postcard and requesting a dataset in an Excel file or in hard copy was the norm, but nowadays, we want to have access in an electronic form, hopefully in relational database format, and we want it right away. As a general rule, these expectations are in sync with technological advancement, but in a recent interview with KQED, one of the candidates for the office of state controller hit the nail on the head by saying the state doesn’t admit what it doesn’t know in terms of technology, so government is often quite behind the curve in terms of adopting and using the relevant technology.”
- Data quality standards and documentation: “Good science and good decision support require access to timely data of known and documented quality, and to answer scientific questions, to inform management decisions. It’s essential to draw upon relevant and appropriate data from multiple sources.”
- Heterogeneous data: “There are lots of data that are of great use but they are in formats that are from the 1970s, pdf files, microfiche or in various formats. To make them accessible and usable, we definitely have to spend some time grappling with how to do that effectively and efficiently. Data in different formats from external sources continue to be added to the legacy database and improve the value of information, but each generation product and home grown systems have unique demands to fulfill in order to store or extract those. So that’s definitely something that most high level managers aren’t really aware of. It’s not a trivial thing to deal with heterogeneous data, but we need to figure out a way to do that.”
- Unanticipated costs: “Data integration costs are fueled largely by items that are difficult to quantify. and thus we can’t predict always how much it will cost to get things done. It’s also important to note that regardless of efforts to streamline maintenance, the realities of a fully functioning data integration system made demand a great deal more maintenance than can often be anticipated, so we need to have a contingency built in here in case we encounter road blocks.”
- Lack of cooperation and coordination: “A lot of it also hinges on the human factor and overcoming the reservations that ‘another person doesn’t know what my data really say that I generated and I want to prevent misinterpretations or misrepresentations of my data that I generated,’ so one entity may not want the data they collect and track at all times transparently visible to others without the opportunity to address the nuances behind a dataset, for example, so that one we also need to tackle and find ways to overcome that.”
Mr. Hoenicke then discussed the suggestions for the path forward:
-

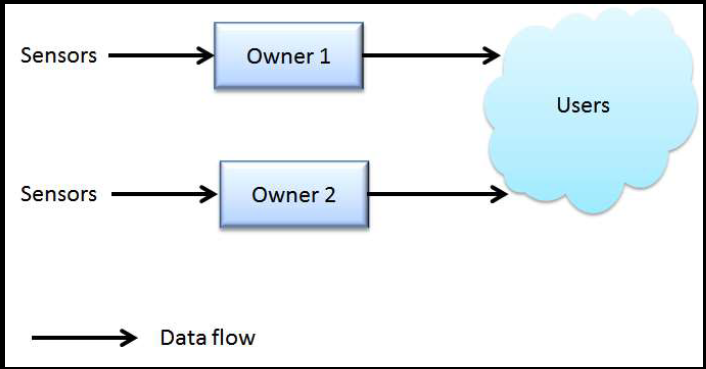
A non-federated data model Sign on to a federated data model: “The integration of California’s existing data repositories into a federated data model will not only add functionality, but it also creates efficiencies,” he said. “So a comprehensive federated data strategy should be adopted by the state to bring all the data together into a virtualized unity, but still preserve the autonomy and the individual data repositories and the stewardship over them.” Mr. Hoenicke then explained what a federated data model is by first presenting a pictorial slide of a non-federated data model. “This is the non federated model where you have to look at all of the data stewards that own the data, and you don’t know how many there are …

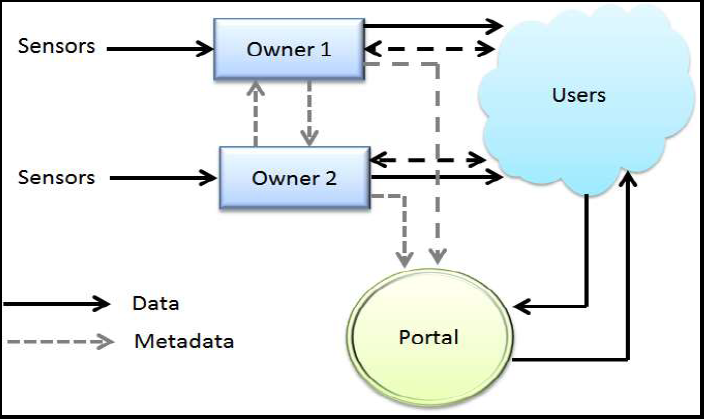
A federated data model whereas if you have a portal that essentially unifies these in virtual form, you can find out that there are many more datasets than you might have imagined,” he said, noting that this is already being implemented somewhat with the California Environmental Data Exchange Network (CEDEN).
- Promote and document data standards: “The next step is to promote metadata standards, so we recommend surveying the state’s data stewards for information regarding standards currently in use, and then the hard work of adopting and incentivizing data standards should prefigure a broader federation effort … Also, participating in the OGC Interoperability Program to provide access and direction to a worldwide community focused on improving interoperability. And California should really avail itself of interjurisdictional workgroups that the California Water Quality Monitoring Council has already set up, so we have a good foundation from which to work; I think the monitoring council has done an incredible job at having a solid foundation already in place that we can now build the next story onto.”
 Require data management plans for all data acquired: Another recommendation in the white paper is to tie future funding opportunities to compliance with existing data sharing policies. “The federal government already requires data sharing to be implemented, and has some data sharing policies in place now. Those should also be clearly articulated with reference to state and to federal laws as appropriate. Let’s make sure that if data generation activities are funded by the state, that certain rules are being followed here.”
Require data management plans for all data acquired: Another recommendation in the white paper is to tie future funding opportunities to compliance with existing data sharing policies. “The federal government already requires data sharing to be implemented, and has some data sharing policies in place now. Those should also be clearly articulated with reference to state and to federal laws as appropriate. Let’s make sure that if data generation activities are funded by the state, that certain rules are being followed here.”- Embrace data of different quality, resolution, sources, as long as attributes are documented: “Just because somebody measures ph with litmus paper doesn’t mean those data are not useful. You just have to figure out what uses you want to subject those results to to have them be useful, and that is a definitely a key point here. Don’t just toss data out because you don’t feel they are high resolution enough.”
- Develop and use web services for data sharing: “The final key recommendation is to develop and use web services for data sharing. Strategic alliances with emerging national and global initiatives are already underway, primarily spearheaded through the water quality monitoring council and through their data management and wetlands monitoring workgroups, and this work must continue and expand.”

“And with that, I am ready for questions,” concluded Mr. Hoenicke.
Question: As this data becomes more available and transparent on the web and so forth, the amount of data is going to have some commercial value. What is the policy with respect to allowing independent commercial entities to access that data, use it, package it, and make it available for profit basis?
“I think public private partnerships are definitely the way to go and I think there are some emerging rules about what level value added constitutes a kind of a new data set or database that private companies can then use for profit,” said Mr. Hoencike.
“Under the president’s open data policy, one of the objectives is to encourage private use of public data to foster investment and market investment,” added Tony Hale. “In California, there is this particular provision where government can actually sell data. It’s one of the few states that has this legal provision. You see this in play when you are trying to get access to California Natural Diversity Database, where there’s a free version and there’s a paid version. That’s a form of licensing where the government is actually selling you data, and I imagine what we do want to encourage is the public use of data for research or for private use. What’s really key is attribution. We want to make sure that we still preserve those lines of attribution; that’s really important, it’s a part of data documentation. It’s part of ensuring we can track data even as it moves from point of origin to point of processing to point of analysis and then end use. It’s really important to capture those transformations, not only for the integrity of the science and the reproducibility of the findings, but also so that we can honor all those different contributors along the way. That’s very much a part of what you will find in the vision white paper … “
Question: Can you talk a little bit about how the Delta science vision is addressing the political cycle versus the science cycle. The political science cycle is more like two to four years, whereas the science cycle takes more like four to six to eight years … long term data sets build information so could you talk a little bit about that?
“One of the quotations I’d like to share with you that came up at the data summit was ‘with every change of administration, the great forgetting sets in’,” said Mr. Hoenicke. “Good ideas or initiatives get pushed sideways or into the background, and I think maybe the science community can make a huge difference in keeping those good initiatives alive and not letting the political process disrupt good initiatives. We’ll have to find champions in independent agencies or organizations that can keep the organizational memory alive and think in longer terms rather than just two or four year political cycles.”
“I want to emphasize for the science action agenda effort and the interim science action agenda, although those are four and two year cycle efforts, it’s not by any means trying to say it’s not in support of ongoing science,” added Lindsay Correa. “Some of those action areas are intended to address ongoing efforts. For example, we heard from several members from the community through interviews that ongoing support of monitoring activities to maintain long term data sets is something that is essential and a priority for many of the organizations that we interviewed as moving forward, so the two and four year cycles of the science action agenda are just means for checking in to say let’s talk about what these priority activities are. It’s not exclusive of those longer term efforts.”
Question: You had mentioned that the data management standards would be something that would need to be developed, but with the flood of data that would come through in a national database, how do you ensure the quality of the data?
“My simple answer is through appropriate data documentation,” said Mr. Hoenicke. “We need to have a basically a floor, common denominator, minimum level of data documentation that is required so that you can see if the dataset can be used for that purpose. The trend is going towards use of different kinds of datasets and very diverse sets of data for purposes that they were not originally intended to be used for, or had a completely different purpose, so data documentation seems to be to me the silver bullet here, if there is one.”
Question: You’re talking about data without at the same time talking about models. Because there’s a huge amount of data that’s acquired and the data will be lacking one specific component that could be used to synthesize the data or at least start to understand the data without a model in the background, so I think it’s coming from a modeling background, this is a real frustration and that you have partial datasets but you’re missing a crucial parameter, and by talking about data without having a model or at least a hypothetical model in the background, I think is an error.
“Absolutely,” replied Mr. Hoenicke. “Maybe that was just an assumption behind the data summit. Number one, our conceptual models need to drive data generation to begin with, just like the adaptive management wheel indicated, but you’re totally right, and that’s why we’re going to have the community based modeling summit in close proximity to the data summit because they have to be linked. Yes, you are completely on the mark.”
Tony Hale
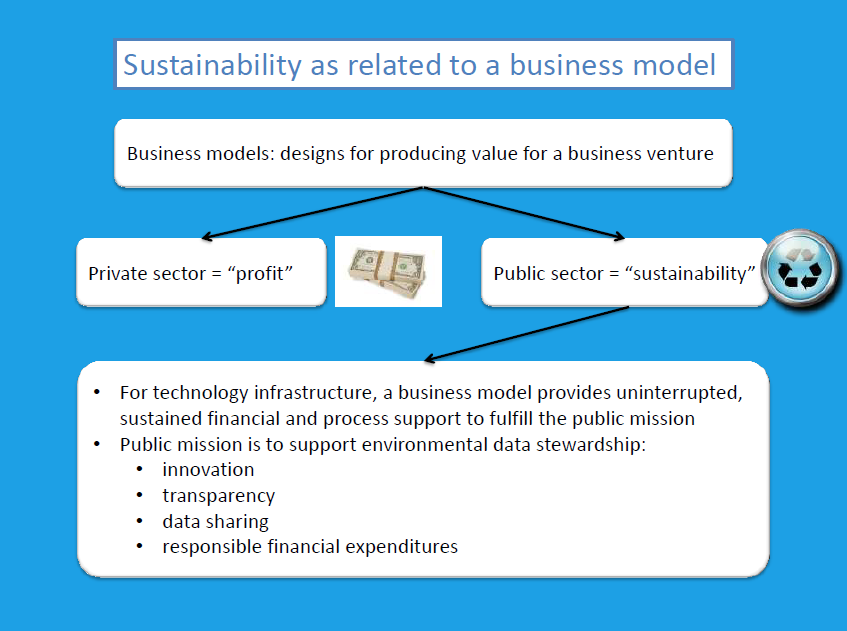
 Tony Hale then took the podium for his presentation on implementing successful business models for addressing technology needs. He began by explaining that a business model in the public context is slightly different than what would be found in private industry. “Within the private sector, a business model is designed to keep things afloat; it’s about sustaining a certain level of profit,” he said. “But within the public sector, it’s about sustainability; it’s about being able to continue your practices in a sustainable way rather than having these gaps of funding that are so inhibiting to progress and to innovation and can often leave projects, particularly technology projects, without the necessary funding to sustain maintenance and continue to support some science findings.”
Tony Hale then took the podium for his presentation on implementing successful business models for addressing technology needs. He began by explaining that a business model in the public context is slightly different than what would be found in private industry. “Within the private sector, a business model is designed to keep things afloat; it’s about sustaining a certain level of profit,” he said. “But within the public sector, it’s about sustainability; it’s about being able to continue your practices in a sustainable way rather than having these gaps of funding that are so inhibiting to progress and to innovation and can often leave projects, particularly technology projects, without the necessary funding to sustain maintenance and continue to support some science findings.”
“As applied to technology infrastructure, we really need to support that public mission through sustainable funding and sustainable business practices that go along with that,” Mr. Hale said. “The public mission would be some of those things we’ve been talking about all along. I hear all of these exhortations about transparency, innovation, and openness, and I think this is great, but how do we get there?”
 “The business model is really about trying to chart a path towards a sustainable way to support the infrastructure,” Mr. Hale said. “The business models need to accommodate data sharing; our business models thus far have been just maintaining data for the sake of maintaining data – collecting data and holding it. Now we’re transitioning to a new framework that demands greater data sharing and that really does require some rethinking.”
“The business model is really about trying to chart a path towards a sustainable way to support the infrastructure,” Mr. Hale said. “The business models need to accommodate data sharing; our business models thus far have been just maintaining data for the sake of maintaining data – collecting data and holding it. Now we’re transitioning to a new framework that demands greater data sharing and that really does require some rethinking.”
The federal government has a open data policy that’s calling for more robust sharing, openness, and interoperability, he said. He explained that interoperability means essentially machine to machine readability, such as using certain standards to ensure that one machine can reliably grab data from another machine and bring into focus. “This is a big change from the way things used to be where data was bound tightly to the machine where it lived. Now data floats freely from machine to machine, and in order to make sure that it can do that, and that’s a good thing, data needs to be interoperable, and that’s really a challenge that we face and that’s part of what data sharing is about.”
California also has some data sharing mandates, such as the California Water Quality Monitoring Council, that speaks to both the need for agency coordination and sharing of data among agencies, as well as the public, but beyond the mandates, there are also some urgent, critical science needs. “We’re facing huge challenges that in and of themselves, require us to coordinate our efforts and to share data in timely ways,” Mr. Hale said.
How do we work across agency boundaries to ensure that the best available science is not isolated in a single silo? “Currently we have these silos of agencies and then we have the data that are tied to those silos as well, so how do we overcome that?” Mr. Hale said. “Data visualization is one of the outputs from data sharing, and I wanted you to understand that one of the key benefits for having machine to machine interoperability is to have really robust communicative data visualization that can account for uncertainty – data visualization that can speak to the public as well as decision makers. That’s a really key payoff for data sharing.”
“One of the risks of moving forward without a strong business model is that we lack a value proposition,” Mr. Hale said. “In other words, there’s not a champion necessarily saying, ‘this what we will get from making changes from the way that we do business’ so making sure that we can clearly articulate that value proposition is so very important.”
We have a lack of understanding of user needs, he said. “We have different groups that need to make use of that data. We have scientists, we have decision makers, we have policy makers, we have the public, and we have various different groups; we need to be able to note and connect those user needs to that value proposition.”
There is a perceived redundancy of services and products, Mr. Hale said. “We want to make sure we aren’t recreating the wheel, but it’s important to distinguish between redundancy of data and redundancy of a lot of tools that make use of that data. We don’t want to create redundant data, that’s really clear; we don’t want one person to have one version of the data and another person to have another version, and that’s why we need to foster that interoperability and that data sharing. But I don’t think it causes great harm for us to have different tools that can make use of the data in very different ways to serve different interests. That’s part of the benefit of today’s world is that useful divergence of data and machine. You can have more than one machine that can make use of the data.”
Currently, there is ineffective coordination. “We don’t have someone who can articulate that value proposition and make sure that we have a clear understanding of user needs, but we need to make sure that someone is empowered, or perhaps a collection of people who can make sure that the coordination happens.”
“Of course, insufficient resources,” said Mr. Hale. “The shortfall in the funding for science to support restoration activities is very humbling. It’s a big gap between what is needed and what is available. And we need to make some headway. It’s through the business model that we can hope to do that.”
Mr. Hale said the paper, ‘The Effect of Funding Fluctuations on Government Funded Software Development,’ talks about what happens when there is a shortfall in funding for software development. “People are hammering away at the creation of software and you’re getting that done, and suddenly there’s this budget shortfall, so then what happens. It’s a greater cost than just sort of pause, wait, and then start again, so that’s what that paper is about.”
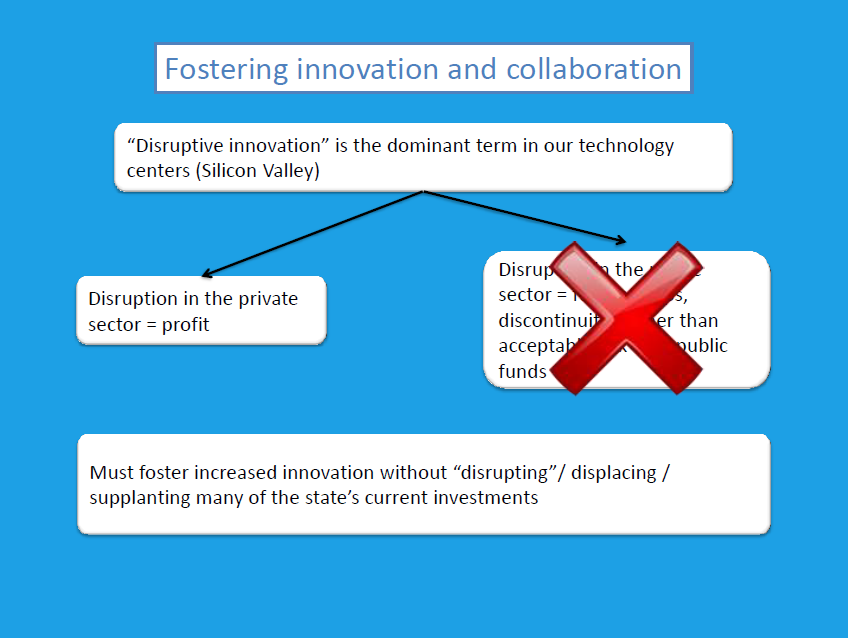 As far as fostering innovation and collaboration within this public sector, the term ‘disruptive innovation’ is a dominant term in our technology centers, he said. “It’s now become a term where people say, oh we’re going to employ this technology, it’s very disruptive. That’s seen as a good thing within Silicon Valley, but within the public sphere, it can result in a feeling of great trepidation that there’s going to be ‘disruption.’ There will be funding gaps, there will be discontinuity – disruption equals discontinuity, and particularly when you are talking about public funds, disruption can be risky. So how do you mitigate that risk, how do you still foster innovation, still foster collaboration, and then contend with that feeling of disruption?”
As far as fostering innovation and collaboration within this public sector, the term ‘disruptive innovation’ is a dominant term in our technology centers, he said. “It’s now become a term where people say, oh we’re going to employ this technology, it’s very disruptive. That’s seen as a good thing within Silicon Valley, but within the public sphere, it can result in a feeling of great trepidation that there’s going to be ‘disruption.’ There will be funding gaps, there will be discontinuity – disruption equals discontinuity, and particularly when you are talking about public funds, disruption can be risky. So how do you mitigate that risk, how do you still foster innovation, still foster collaboration, and then contend with that feeling of disruption?”
“Part of it is that we must foster that innovation in evolutionary rather than revolutionary ways,” Mr. Hale said. “We need to build upon past investments rather than completely pushing them aside, and there are ways to do that while still fostering innovation. One particular way might be to embrace open source software, so rather than adopting a single proprietary vendor that we can have diversity … you can have a diversity of tools that you can apply to your problem and that might come with a blend of open source and proprietary, but right now, a lot of times our open source software is shunted aside.”
 “Among the recommendations, is to have data federation, as Rainer mentioned, where you have multiple repositories coming together into a virtual hole,” Mr. Hale said. “What’s really important is before you can do this, you need to establish certain standards so that you can make that data interoperable and it allows collective power while still preserving the individual agency mandates and individual control over their different data repositories. So it’s not threatening those repositories, it’s really enhancing them.”
“Among the recommendations, is to have data federation, as Rainer mentioned, where you have multiple repositories coming together into a virtual hole,” Mr. Hale said. “What’s really important is before you can do this, you need to establish certain standards so that you can make that data interoperable and it allows collective power while still preserving the individual agency mandates and individual control over their different data repositories. So it’s not threatening those repositories, it’s really enhancing them.”
“Another recommendation is to empower a task force to address the gaps in the state’s business model,” said Mr. Hale. “Some risks can be overcome with an inventory analysis or a lack of understanding of user needs can be through market segmentation analysis. Redundancy of services and products can be through a cost benefit analysis. These are all things that require a lot of rigor and some time. The insufficient resources can be through different funding models, which we’ve articulated as different potential possibilities within the white paper, and then ineffective coordination can be somehow overcome through development of common standards, which is more than just coming up with a piece of paper that say this is our standards, but it’s about coordinating efforts to maintain those standards over time.”
 “There are different funding opportunities, including public-private partnerships, technology innovation funds, grant funding, and federal program partnerships,” Mr. Hale said. “There are also ways to frame benefits to the different user groups, to agencies talking about what are the benefits of taking on this new business model, to scientists, to public stakeholders. Each different audience is going to have a different take on what those benefits might be.”
“There are different funding opportunities, including public-private partnerships, technology innovation funds, grant funding, and federal program partnerships,” Mr. Hale said. “There are also ways to frame benefits to the different user groups, to agencies talking about what are the benefits of taking on this new business model, to scientists, to public stakeholders. Each different audience is going to have a different take on what those benefits might be.”
“So with that … “
More from the 2014 Bay Delta Science Conference …
 Help Maven fill the funding gap and keep unique content like this flowing …
Help Maven fill the funding gap and keep unique content like this flowing …

Make a tax-deductible donation or “join the club” today!
